9. 웹 크롤러 설계 본문
1. 웹 크롤러의 정의 및 주요 용도
웹 크롤러(로봇 또는 스파이더)는 웹 상의 새로운 콘텐츠를 찾아 수집하는 시스템으로, 주된 활용 사례는 다음과 같다.
- 검색 엔진 인덱싱: Googlebot처럼 수집한 페이지를 검색 색인으로 구축
- 웹 아카이빙: 장기 보관용 정보 수집
- 웹 마이닝: 데이터 마이닝을 통한 지식 추출
- 웹 모니터링: 저작권·상표권 침해 감시
2. 문제 이해 및 설계 범위 확정
기본 알고리즘은 “시드 URL → 페이지 다운로드 → 링크 추출 → 반복”이지만,
대규모 크롤러 설계 전에는 다음과 같은 질문을 통해 요구사항을 명확히 해야 한다:
- 크롤러의 주된 용도는? (예: 검색 인덱스 생성)
- 월간 수집 페이지 수는? (예: 10억 페이지)
- 신규·변경 페이지도 재수집할 것인가?
- 수집한 페이지 보관 기간은? (예: 5년 저장)
- 중복 콘텐츠 처리 방식은? (예: 중복 페이지 무시)
위 요구 사항을 확정한 이후 크롤러가 갖추어야 할 핵심 속성을 고려하면 아래와 같다.
- 규모 확장성: 수십억 페이지 병행 처리
- 안정성(robustness): 잘못된 HTML·장애·악성 링크 대응
- 예절(politeness): 대상 사이트에 과도한 요청 자제
- 확장성(extensibility): 이미지·비디오 등 신규 콘텐츠 유형 지원 용이
3. 개략적 규모 추정
- 월간 10억 페이지 → 평균 500 KB/page → 500 TB/月
- 5년 보관 시 500 TB × 12 개월 × 5 년 = 약 30 PB 필요
- QPS = 10억 / (30 × 24 × 3600) ≈ 400 page/sec, 피크는 약 800 page/sec
4. 개략적 설계안

주요 컴포넌트:
- 시드 URL 집합: 크롤링 시작점 설정 : 주제/지역특색/인기도 에 따라 부분집합으로 나누어 세트를 만드는 전략 사용 가능
- 미수집 URL 저장소(Frontier): FIFO 큐 구조로 관리
- HTML 다운로더 & 도메인 이름 변환기: HTTP 다운로드 및 DNS 조회
더보기
웹 크롤러가 URL에서 바로 HTML을 받아올 수 없고, 도메인 이름 변환기(DNS resolver)가 반드시 필요한 이유는 크게 다음과 같습니다.
- 네트워크 통신의 기본
- HTTP 요청은 결국 IP 주소로 TCP 연결을 맺은 뒤에야 이루어집니다.
- “www.example.com” 같은 도메인은 사람이 읽기 편한 식별자일 뿐, 실제 패킷 전송에는 IP가 필요하기 때문에 반드시 DNS 조회 과정을 거쳐야 합니다.
- 성능 최적화 및 부하 분산
- 대규모 크롤러는 초당 수백~수천 건의 요청을 처리하기 때문에, OS 기본 DNS 캐시만으로는 충분치 않습니다.
- 자체 DNS 캐시를 두면 반복적인 조회 비용을 크게 줄이고, TTL(유효 시간)에 맞춰 갱신함으로써 불필요한 외부 조회를 방지할 수 있습니다.
- CDN·로드밸런싱 대응
- 많은 대형 웹사이트는 CDN(콘텐츠 전송 네트워크)이나 로드밸런서를 통해 다수의 IP를 배포합니다.
- 도메인 변환기를 직접 운영하면, 복수의 IP 중 어떤 서버로 연결할지(예: 라운드 로빈, 지리적 근접성 기반) 전략을 커스터마이징할 수 있습니다.
- 장애 복구와 안정성 강화
- 외부 DNS 서버 장애나 네트워크 지연 시 자체 변환기를 이용해 장애 격리(fault isolation)가 가능합니다.
- DNS 조회 실패 시 재시도 정책이나 대체 DNS 서버를 즉시 적용할 수 있어, 크롤러 전체의 안정성을 높여 줍니다.
- 정책 기반 요청 스케줄링
- 호스트(도메인)별로 요청 간격(politeness)을 다르게 관리하려면, “example.com → IP” 매핑 정보를 명확히 알고 있어야 합니다.
- 동일 도메인에 여러 IP가 있어도 한 묶음으로 처리하거나, 반대로 IP 단위로 세밀하게 조정할 수도 있습니다.
- 콘텐츠 파서: HTML 유효성 검사 및 파싱 (사용 리소스가 크기에 별도 컴포넌트로 구현)
- 중복 컨텐츠 확인: 이미 저장한 페이지인지 확인. 웹페이지의 해시 값 비교
더보기
- “전혀 변하지 않은(바이트 단위 동일)” 페이지만 걸러낼 거라면, MD5/SHA로 바로 해시 비교가 충분합니다.
- 실질적 내용이 같은 페이지를 찾아내려면, HTML 정규화 후 해시하거나 SimHash·MinHash 같은 근사 해싱 기법을 도입해야 합니다.
- 대규모 크롤러 설계에서는 보통 이 둘을 조합해서 “완전 동일”은 빠른 암호학 해시, “거의 동일”은 SimHash 등으로 2단계 검사하는 방식으로 운영합니다.
- 콘텐츠 저장소: 디스크에 보관, 인기 페이지는 메모리 캐시
- URL 추출기 & URL 필터: 링크 추출 및 크롤링 대상 필터링
- 방문한 URL 확인기: 또 너냐..! 블룸 필터!
- URL 저장소: 방문 URL 기록
5. 상세 설계
어떤 기본 탐색 기법을 사용할 것인가?
- 그래프 탐색 기법: 웹은 diredted graph. 일반적으로 BFS 선호(우선순위 큐 활용)
- DFS를 사용할 경우, 깊이 가늠이 어렵다.
- BFS를 사용하면 병렬로 다음 depth의 페이지를 다운로드 할 수 있다.
- 대신, 한개의 서버에 다수의 요청이 몰리게 되고, impolite 크롤러로 간주된다.
URL Frontier (미수집 URL 저장소 구현)
- 예절 구현: 호스트별 FIFO 큐, 큐 라우터·매핑 테이블·큐 선택기·작업 스레드 구성
더보기
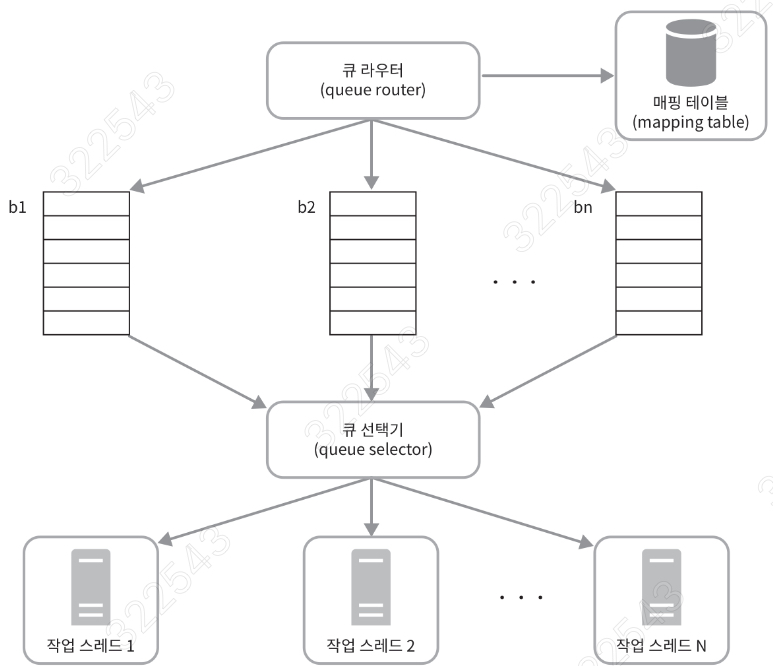
예절(Politeness) 정책 개요
웹 크롤러의 예절이란 “짧은 시간 안에 동일 호스트에 과도한 요청을 보내지 않는 것”을 의미.
이를 지키지 않으면 대상 서버에 부하를 줄 뿐 아니라, 운영자 불만이나 차단으로 이어질 수 있다. (DDoS 인가??)
폴-라이트 한 크롤러의 1 원칙은 "동일 웹 사이트에 대해 한번에 한개의 요청만 보낸다" 이다.
호스트 분리 및 다중 큐 아키텍처
- 큐 라우터(Queue Router): 새로 수집한 URL을 호스트별로 정해진 Back-Queue(예: b₁, b₂, … bₙ)로 분배.
- 매핑 테이블(Mapping Table): 호스트 이름 → 큐 번호 매핑을 저장해, 같은 호스트의 URL이 항상 동일한 큐에 들어가도록.
- FIFO 큐: 각 큐는 오직 한 개의 호스트 URL만 보관하며, 큐 내에는 순서대로 처리 대기.
- 큐 선택기(Queue Selector) & 작업 스레드:
- 큐 선택기는 여러 Back-Queue 중 비어 있지 않은 큐를 라운드 로빈 혹은 우선순위 기반으로 선택.
- 각 작업 스레드는 자신이 선택한 큐에서만 URL을 꺼내 내려받기를 수행함으로써, 한 호스트에 동시 요청이 1개로 제한.
robots.txt 및 Crawl‑Delay 준수
- 로봇 제외 프로토콜: 크롤러는 우선 robots.txt를 내려받아, Disallow 규칙에 따라 수집 대상 경로를 필터링.
- Crawl‑Delay: 비표준 지시자지만, robots.txt에 명시된 경우 해당 호스트에 대한 요청 간 최소 지연 시간을 반영해야 한다..
- 적용 예시: Googlebot, Yahoo!, MSN 등 주요 검색 엔진이 Crawl-Delay를 활용해 과도한 요청을 방지.
지연 관리 및 타이밍 힙
- 타이밍 힙(Timing Heap) 또는 DelayQueue를 사용해, 각 Back-Queue별로 “다음 요청 가능 시각”을 기록·관리.
- 작업 스레드가 URL을 요청하기 전에, 힙에서 가장 이른 시점을 확인하여 아직 도달하지 않았으면 대기했다가 실행.
- Mercator 방식: 요청간 지연 시간을 동적으로 저장하는 방식. adaptive politeness를 적용할 수 있다.
- 우선순위 관리
더보기
- 우선순위 큐(Priority Queue) 활용
- 단순 FIFO가 아닌 우선순위 큐로 구현하여, 수집 순서를 동적으로 조정.
- 우선순위 결정 기준 예시
- Depth: 시드로부터 가까울수록(작은 depth) 높은 우선순위
- Domain 중요도: 도메인별 가중치(예: 대형 뉴스 사이트 > 개인 블로그)
- 변경 빈도: 과거 크롤링 간격에서 변경이 자주 감지된 URL 우선
- PageRank 추정치: 내부 링크 구조 기반 중요도 스코어
- 사용자 지정 규칙: 특정 키워드, URL 패턴 매칭 시 가산점
- 각 URL에 대해 위 요소를 합산(or 가중합)하여 priority = w₁·(1/depth) + w₂·domain_score + … 형태의 점수를 부여하고, 높은 점수일수록 먼저 처리
- 호스트별 큐 + 우선순위 조합
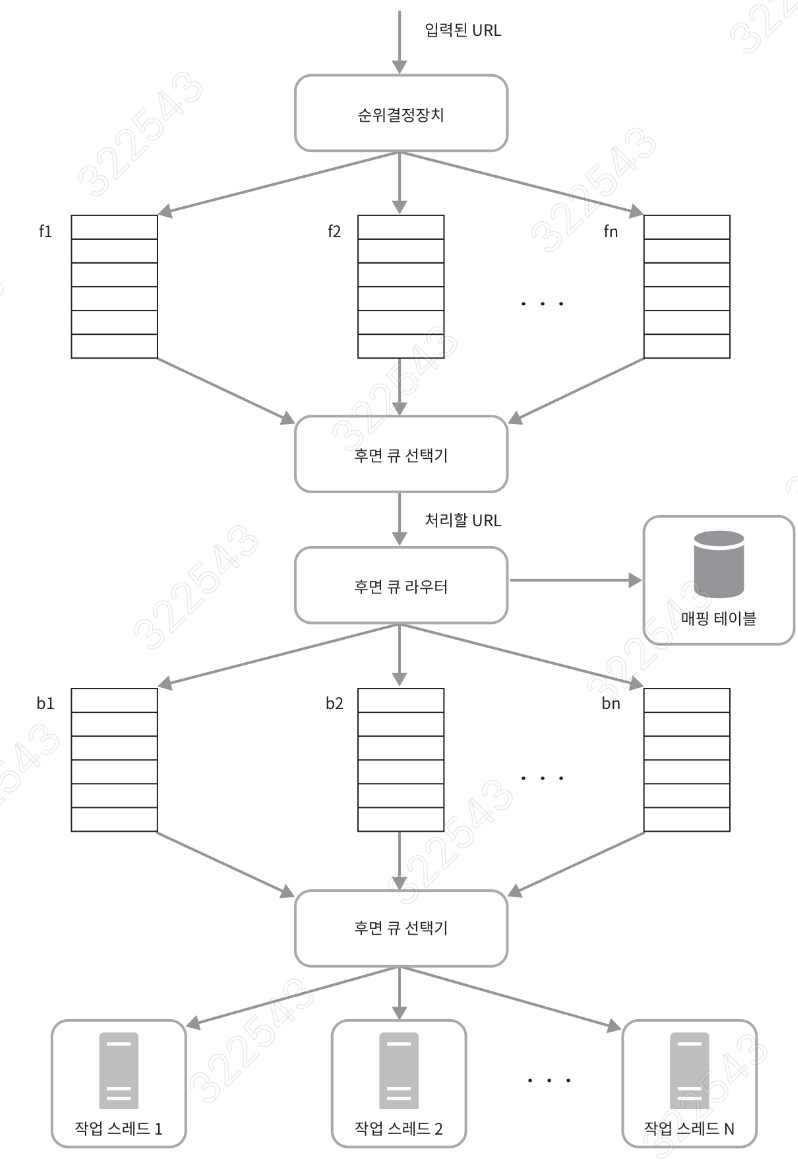
- 단계 1: Queue Router
- URL을 호스트별 Back-Queue에 배분
- 단계 2: Host‑Level Priority Queue
- 각 호스트 큐 내부도 우선순위 큐로 관리하여, 동일 호스트 안에서도 더 중요한 페이지를 먼저 크롤링
- 단계 3: 글로벌 Queue Selector
- 여러 호스트 큐를 라운드 로빈 혹은 우선순위(예: 남은 대기시간 짧은 순)로 선택
- 정책 예시: “전체 Frontier에서 우선순위 상위 100개의 URL 중, 각 호스트별 1개씩 번갈아가며 크롤링”
- 단계 1: Queue Router
- Politeness + Priority 동시 관리
- DelayQueue를 활용해, 각 호스트 큐마다 “다음 요청 가능 시각(nextAvailableTime)”을 기록
- 글로벌 큐 선택 시,
- 현재 시간이 nextAvailableTime을 지난 호스트 큐를 필터
- 남은 대기시간이 짧은 호스트 큐 중 우선순위 높은 URL을 선택
- 이로써 예절(호스트당 동시 1연결, 최소 지연)과 우선순위(중요도 기반 순서)의 절충 가능
- 신선도(freshness) 및 재크롤링 우선순위
- 페이지 변경 빈도 분석 결과를 기반으로, “가장 자주 변하는” 페이지일수록 재크롤링 우선도 상향
- 재크롤링 스케줄 표: revisit_interval = base_interval / change_rate
- Frontier에 들어가는 재방문 URL에도 위 우선순위 로직 동일 적용
- 장애 대응과 재할당 전략
- 스레드 장애·다운 시, 해당 스레드가 점유하던 URL을 즉시 우선순위 큐로 반납
- Consistent Hashing 대신, Priority Queue에서 재분배하여 “중요도가 높은 URL이 지연되지 않도록” 보장
HTML 다운로더 최적화
- 분산 크롤링 (URL 공간 파티셔닝 후, 여러 서버에 분산하여 처리)
- DNS 결과 캐시 (10–200 ms 블로킹 방지)
- 지역성: 대상 서버과 지리적 근접성
- 대기 시간이 길어지면 부담임. 짧은 타임아웃 설정
6. 안정성(robustness) 강화
- 안정 해시(consistent hashing): 다운로더 간 부하 균등 분산
- 지속적 상태 기록: 장애 시 복구용 크롤링 상태·데이터 저장
- 예외 처리: 전체 중단 없이 우아한 작업 지속
- 데이터 검증: 오류 방지 위한 입력 검증
7. 추가 고려사항
- 서버 측 렌더링을 통한 동적 URL 검색
- 불량 페이지 필터링: 스팸·저품질 차단
- DB 다중화·샤딩: 저장소 확장성 확보
- 수평적 확장성, 가용성·일관성·안정성
- 데이터 분석 솔루션 연동
'ETC' 카테고리의 다른 글
| 10. 알림 시스템 설계 (0) | 2025.04.22 |
|---|---|
| Closure Table을 이용한 File Authority 적용기 (0) | 2025.03.17 |
| RDBMS 에서 tree structure 다루기 (0) | 2025.03.17 |
| [Java] StringBuilder 주요 메소드 (0) | 2025.01.21 |
| Cursor AI 사용기 (9) | 2024.11.07 |
'ETC' 관련글
더보기



Comments